Pictorial Representation of Hadoop Eco Systems is as shown
below.
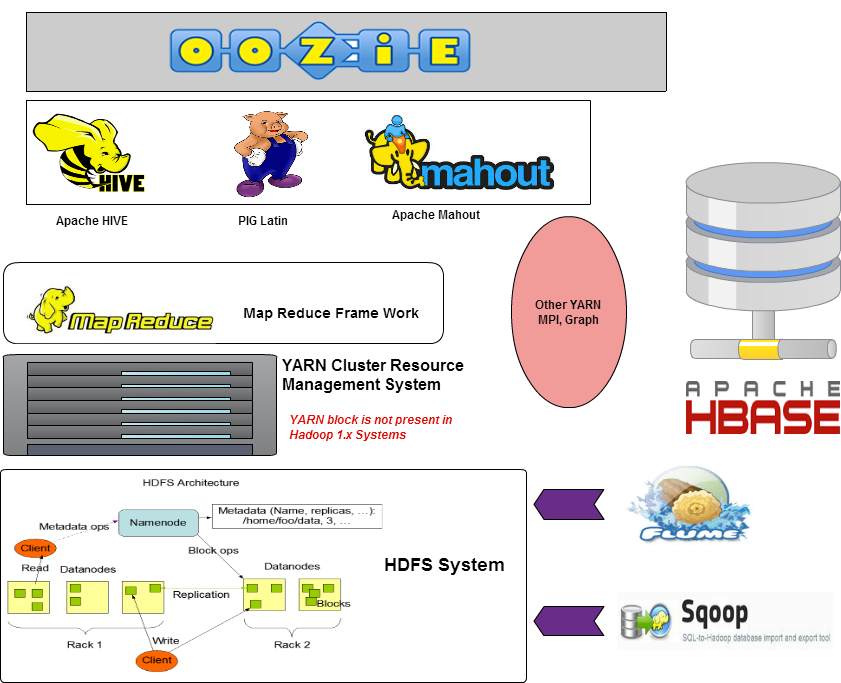
YARN system are not present in first generation of Hadoop
development. (Hadoop 1.x versions).
Remember, we do not have Yarn Cluster Resource Management System in Hadoop 1.x version which was a disadvantage as any other operations on HDFS, has to be converted to MR code (Map-Reduce Algorithm) and then it use to process the data.
With help of YARN (Yet Another Resource Negotiator) in place, we can process HDFS files directly without converting it to into MR code, with the help of some additional languages such as Spark, Giraffe etc.,
Remember, we do not have Yarn Cluster Resource Management System in Hadoop 1.x version which was a disadvantage as any other operations on HDFS, has to be converted to MR code (Map-Reduce Algorithm) and then it use to process the data.
With help of YARN (Yet Another Resource Negotiator) in place, we can process HDFS files directly without converting it to into MR code, with the help of some additional languages such as Spark, Giraffe etc.,
An amazing blog ever. Thanks
ReplyDeleteBig Data and Hadoop Online Training