Many times, When we come to a situation to start our work from already developed project, Where Foreign Keys and Primary Keys are already developed in Database, It is Necessary for us to know which table is referring to which table as with Primary Key and Foreign Key Constraint.
For this Purpose, We have System Tables which will Help us to find the Primary key and Foreign key and related Tables.
The query is as follows:
For this Purpose, We have System Tables which will Help us to find the Primary key and Foreign key and related Tables.
The query is as follows:
USE ADVENTUREWORKS2008 GO SELECT OBJECT_NAME(SFK.PARENT_OBJECT_ID) AS [FORIEGN KEY TABLE] ,COL_NAME(SFKC.PARENT_OBJECT_ID, SFKC.PARENT_COLUMN_ID) AS [FORIEGN KEY COLUMN] ,OBJECT_NAME(SFK.REFERENCED_OBJECT_ID) AS [PRIMARY KEY TABLE] ,COL_NAME(SFKC.REFERENCED_OBJECT_ID, SFKC.REFERENCED_COLUMN_ID) AS [PRIMARY KEY COLUMN] FROM SYS.FOREIGN_KEYS AS SFK INNER JOIN SYS.FOREIGN_KEY_COLUMNS AS SFKC ON SFK.OBJECT_ID = SFKC.CONSTRAINT_OBJECT_ID
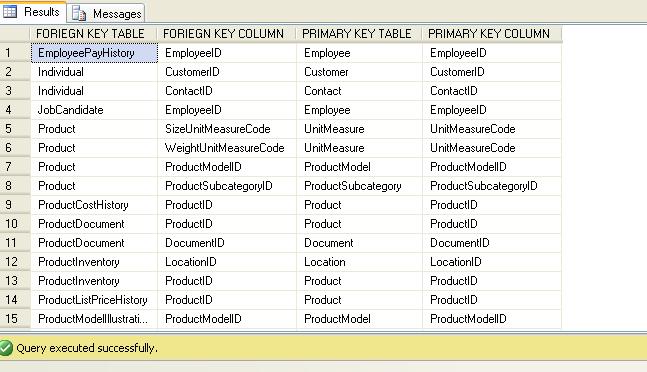
Here I'm trying to find Related tables under Primary key and
Foreign key Constraint in AdventureWorks2008 Database.
Here,
--OBJECT_NAME: Returns the database object name for schema-scoped objects.--COL_NAME: Returns the name of a column from a specified corresponding table identification number and column identification number.--SYS.FOREIGN_KEYS: Contains a list of all FOREIGN KEYS in the database. It contains one row per FOREIGN KEY.--SYS.FOREIGN_KEY_COLUMNS: Contains a row for each column, or set of columns, that comprise a foreign key.
Comments
Post a Comment